Hadoop ecosystem dominates big data landscape, though its strong position appears to change. Apache Spark has drawn attention by professionals around the world. Prominent big data companies like IBM and Cloudera have recently announced their support for Spark.
What is Apache Spark?
Apache Spark is an open-source engine for large-scale computing, targeted to analyze big data.
Due to its batch-oriented nature Hadoop is not fast enough to handle ever-growing demand for real-time analytics. Spark promises that its processing of data is 100 times faster compared to Hadoop. This fact alone has increased the interest for Spark.
Hadoop API is pure Java while Spark API supports also Scala and Python in addition to Java. High-level language support makes Spark more usable. R language is also supported by Spark.
Spark Has Core Libraries and Community Adds New Ones
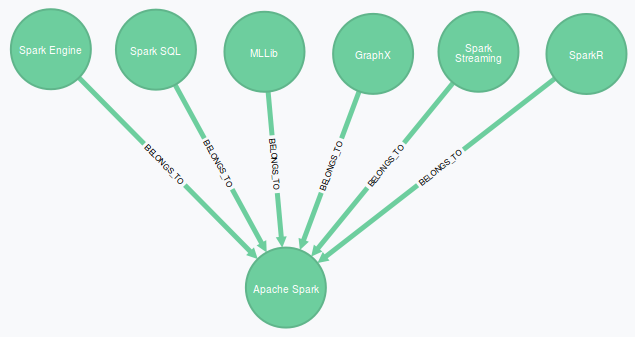
Just like Hadoop, Spark has a collection of built-in libraries which run on top of Spark core engine:
- Spark SQL (formerly Shark) allows to mix SQL queries with Spark API calls. Spark SQL is compatible with HiveQL and can connect to databases using JDBC and ODBC.
- MLLib is a machine learning library, which supports several machine learning algorithms like tree-based and classification algorithms.
- GraphX provides API to handle graphs and collections. This API includes several graph algorithms like PageRank.
- Spark Streaming allows to combine both interactive and batch queries in the same stream for example to handle historical data.
- SparkR is a library to access Spark API from R.
In addition to build-in libraries a number of additional Spark libraries are emerging. These libraries provide access to other platforms like Amazon Redshift.
Choose Spark Or Hadoop – Or Both of Them?
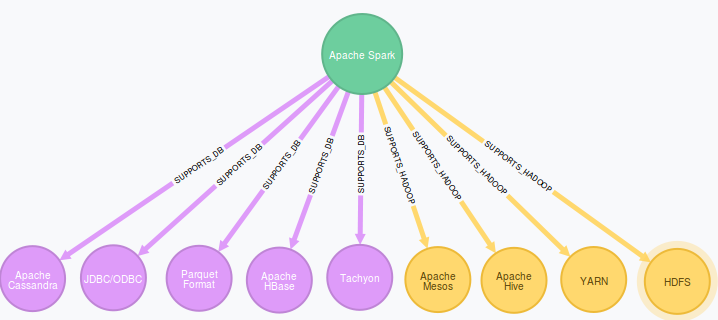
Spark is a platform of its own and can be used in a standalone mode, albeit Spark can also coexist with Hadoop. Eg. Hadoop’s slowish MapReduce engine can be replaced by quicker Spark Engine.
If you start planning a big data architecture from scratch, Spark would be the preferred platform to handle large data volumes in a fast manner. However, existing Hadoop environment can also be enhanced by Spark components.
Spark Support Grows Quickly Among Platform Providers
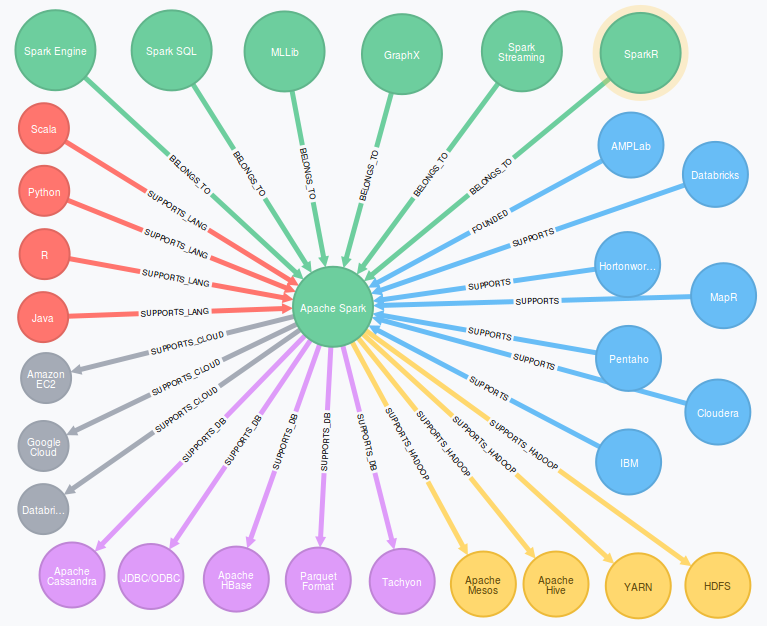
Spark originates from AMPLab (Algorithms, Machines, People) at UC Berkeley, but nowadays Apache Software Foundation manages Spark open-source libraries. The founding team for Spark has created a company called Databricks to provide a cloud environment for Spark.
Major big data companies like IBM, Cloudera, Hortonworks, Pentaho and MapR have announced support for Spark. These companies provide Spark as part of their big data stack, which mainly consists of Hadoop components.
What Is the Future Of Apache Spark Ecosystem
Before Spark would be a viable solution for a large-scale enterprise deployment, some issues needs to be addressed: concurrency and scalability will have to be revisited to improve scalability in large environments.
User-friendly tools for business analysts is a requirement for an efficient use of analytics on top of Spark platform. Spark requires programming skills, albeit Scala does support high-level languages like Python.
Both Spark and Hadoop are currently bleeding edge technology. Stable releases are mandatory for wider adoption of both platforms.
Competition for the big data landscape is fierce and new platforms and components appear constantly. The future looks bright for Spark ecosystem. More companies will definitely join the Spark ecosystem as Spark matures over time.

Hey, could I use your graphics in an article about spark, being from Neo4j of course I’d love to use the graph viz.
Do you by chance still have the SVG exports?
Thank you for your feedback. Neo4J is an excellent tool for modeling complex relations. I’m glad these graphs are useful for your article.
Merja